목차
인덱스란?
인덱스는 무작위로 저장된 데이터 집합에서 원하는 데이터를 쉽고 빠르게 찾을 수 있도록 제공되는 하나의 오브젝트이다.
즉, 요구 조건에 맞춰 테이블을 검색할 때 테이블 전체를 읽어내며 찾는 것이 아니라, 먼저 인덱스의 키로 조건을 탐색하고 함께 저장된 행의 주소값을 통해 테이블의 다른 열을 참조하는 방식으로 수행된다.
인덱스는 흔히 책의 목차로 비유되는데, 책 속의 많은 내용 중에서 원하는 내용을 찾고자 할 때 목차를 통해 쉽게 페이지 번호를 알아낼 수 있기 때문이다.
책이 두꺼울수록, 목차가 세분화될수록 원하는 내용의 페이지를 정확하게 찾을 수 있으며, 마찬가지로 인덱스도 많은 데이터 안에서 찾으려는 조건이 상세할수록 역할은 더욱 분명해진다.
MSSQL에서 인덱스를 생성하는 기본 구문은 다음과 같다.
CREATE INDEX 인덱스명 ON 테이블명 (컬럼명)인덱스는 각 테이블마다 별도로 관리되며 CREATE INDEX 명령을 통해 생성할 수 있다.
키로 사용되는 열은 LOB(Large Object) 타입이거나 900 Byte (SQL Server 2016 버전부터 비 클러스터형 인덱스는 1700 Byte까지 지원) 이상인 데이터 타입은 사용할 수 없으며 정의된 키값은 쿼리문을 통해 인덱스가 참조될 때 조건절을 탐색하는 기준으로 사용된다.
생성된 인덱스는 B-Tree (Balanced-Tree) 구조로 저장된다.


인덱스 페이지 구조는 Root Level, Intermediate Level, Leaf Level의 3단계로 구분된다.
Root Level과 Intermediate Level은 각 하위 Level 페이지의 첫번째 인덱스 키값과 함께 해당 페이지의 위치를 나타내는 포인터 역할을 한다.(위 구조 참조)
Leaf Level의 페이지는 인덱스 키값을 기준으로 정렬된 데이터를 저장한다.
Intermediate Level 페이지는 많아지거나 존재하지 않을수도 있다.
키 값이 같을 땐, RID순으로 정렬된다.
Leaf Level은 항상 키 값 순으로 정렬되어있으므로, Range Scan (범위 스캔 : 검색조건에 해당하는 범위만 읽다 멈춤)이 가능하고, 정방향과 역방향 스캔이 둘다 가능하도록 양방향 연결 리스트 (Double Linked List) 구조로 연결되어 있다.
SQL Server는 인덱스 구성 열이 모두 null인 레코드도 인덱스에 저장한다.
+)
Oracle에서 인덱스 구성 열이 모두 null인 레코드는 인덱스에 저장하지 않는다.
반대로 말하면 인덱스 구성 열 중 하나라도 null 값이 아닌 레코드는 인덱스에 저장한다.
null값을 Oracle은 맨 뒤에 저장하고 SQL Server는 맨 앞에 저장한다.
인덱스의 종류
인덱스는 크게 클러스터형 인덱스(Clustered Index)와 비 클러스터형 인덱스(Non-Clustered Index)로 나누어진다.
클러스터형 인덱스는 테이블 자체를 인덱스로 만드는 형태로, 인덱스의 리프(Leaf) 페이지가 곧 데이터 페이지가 된다.
키값으로 정의된 열을 기준으로 정렬된 상태가 유지되며, 테이블의 구조가 변경되는 형태이기 때문에 클러스터형 인덱스는 테이블마다 1개만 생성할 수 있도록 제한된다.
비 클러스터형 인덱스는 테이블과는 독립적으로 생성되며 정의된 키값과 함께 RID(RowID : 테이블의 행 위치 주소)를 저장하여 관리한다.
마찬가지로 키값을 기준으로 정렬된 상태가 유지되며 최대 999개까지의 비 클러스터형 인덱스를 생성할 수 있다.
클러스터형 인덱스 (Clustered Index)


클러스터형 인덱스는 이 자체로써 테이블로 사용되며, 리프 페이지에 모든 데이터를 포함하고 있기 때문에 키로 사용된 Birth 열을 제외한 나머지 열은 정렬되지 않은 상태로 저장된다.
클러스터 인덱스도 일반적인 B-Tree 인덱스 구조를 사용하지만, 해당 키 값을 저장하는 첫번째 데이터 블록만 가르킨다는 점에서 다르다.
클러스터 인덱스의 키 값은 항상 Uniqie(중복 값이 없음)하며, 우측 사진과 같이 테이블 레코드와 1:N 관계를 갖는다.
일반 테이블에 생성한 인덱스 레코드는 테이블 레코드와 1:1 대응 관계를 갖는다는 점과 다른 양상을 보인다.
이런 구조적 특성 때문에 클러스터 인덱스를 스캔하며 값을 찾을 때는 Random 엑세스가 값 하나당 한번씩만 발생한다. (클러스터 체인을 스캔하며 발생하는 Random 엑세스 제외)
클러스터에 도달해선 Sequential 방식으로 스캔하기 때문에 넓은 범위를 검색할 때 유리하다.
새로운 값이 자주 입력( : 새 클러스터 할당) 되거나, 수정이 자주 발생하는 열 ( : 클러스터 이동)은 클러스터 키로 선정하지 않는 것이 좋다.
- 넓은 범위를 주로 검색하는 테이블
- 크기가 작고 NL Join으로 반복 룩업하는 테이블
- 칼럼 수가 적고 로우 수가 많은 테이블
- 데이터 입력과 조회 패턴이 서로 다른 테이블
클러스터형 인덱스는 위와 같은 상황에서 유용하다.
클러스터형 인덱스 예시 : 데이터 입력과 조회 패턴이 서로 다른 테이블
마지막 항목에 대해 추가적인 내용은 다음과 같다.
어떤 회사에 100명의 영업사원이 있다고 하자. 영업사원들의 일별 실적을 집계하는 테이블이 있는데, 한 페이지에 100개 레코드가 담긴다. 그러면 매일 한 페이지씩 1년이면 365개의 페이지가 생긴다.
실적등록은 이처럼 일자별로 진행되지만 실적조회는 주로 사원별로 이루어진다.
예를들어, 아래 쿼리가 일반적으로 가장 많이 수행된다고 하자.
SELECT
SUBSTRING(일자, 1, 6) AS 월
SUM(판매금액) AS 총판매금액
AVG(판매금액) AS 평균판매금액
FROM 영업실적
WHERE 사번 = 'S1234'
AND 일자 BETWEEN '20090101' AND '20091231'
GROUB BY SUBSTRING(일자, 1, 6)만약 비 클러스터형 인덱스를 이용한다면 사원마다 365개 데이터 페이지를 Random 엑세스 방식으로 읽어야 한다.
특정 사원의 1년치 영업실적이 365개 페이지에 흩어져 저장되어 있기 때문이다.
이처럼 데이터 입력과 조회 패턴이 서로 다를 때, 아래와 같이 사번이 첫 번째 정렬 기준이 되도록 클러스터형 인덱스를 생성해 주면, 한 페이지만 읽고 처리를 완료할 수 있다.
CREATE CLUSTERED INDEX 영업실적_IDX ON 영업실적(사번, 일자);
비 클러스터형 인덱스 (Non-Clustered Index)
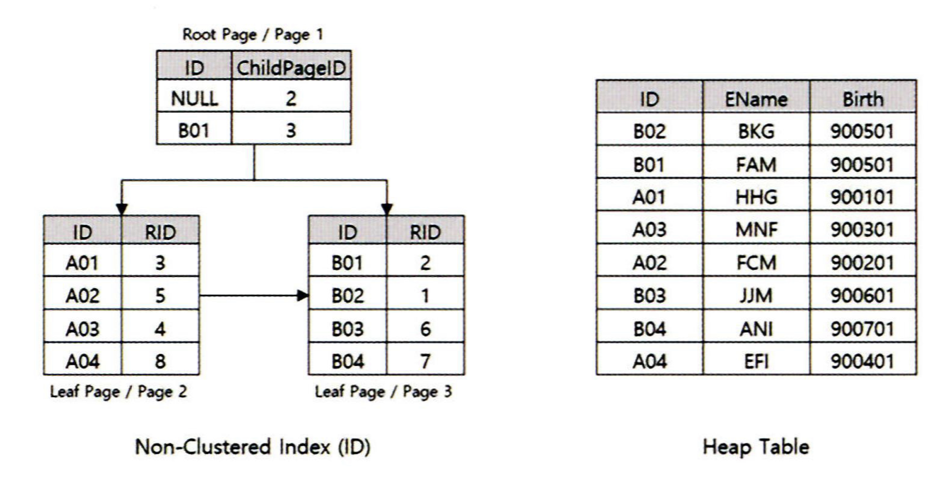
비 클러스터형 인덱스는 테이블과는 독립적으로 생성되기 때문에 정의한 키 열과 함께 테이블 각 행의 포인터가 되는 RID 값이 저장된다.(위 그림에선 RID를 테이블의 행 순서로 정의함)
실제로는 각 행을 구분하는 식별자로 파일 번호 + 페이지 번호 + 슬롯 번호 가 혼합되어 생성된다.
클러스터형 인덱스 + 비 클러스터형 인덱스
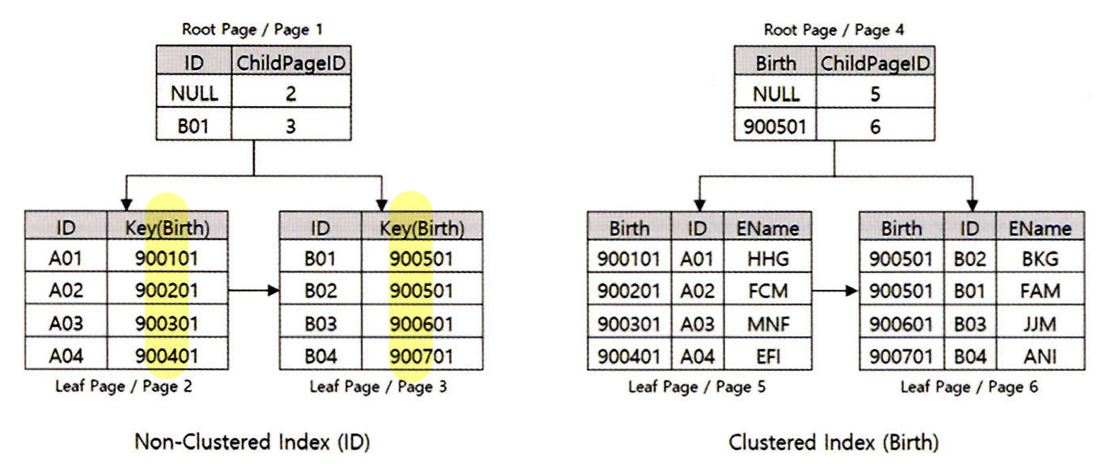
비 클러스터형 인덱스는 클러스터형 인덱스가 존재하게 되면 RID값이 아닌 클러스터형 키를 같이 저장하여 키값으로 행의 위치를 구분하게 된다.
테이블과 인덱스를 통한 스캔 방식
데이터를 조회하기 위해 사용되는 방법으로는 Scan과 Seek가 있다.
Scan은 테이블 전체 혹인 인텍스 전체를 읽어내는 방식이며 Seek는 인덱스를 통해 조건에 해당하는 특정 범위만을 읽어내는 방식이다.
1. 테이블 스캔 (Table Scan)
테이블 스캔은 클러스터형 인덱스가 아닌 테이블 전체를 읽어내며 조회하는 방식이다.

위 그림은 Employee 테이블에서 ID = 'A03' 조건에 해당되는 데이터를 조회할 때의 스캔 범위를 표현한 것이다.
Employee 테이블은 현재 인덱스가 없다고 가정하고, 데이터가 무작위로 저장되어 있는 상태라고 하자.
최종적으로 원하는 결과는 1건이지만, 요구 조건에 만족하는 다른 데이터가 존재하지 않는다는걸 보장할 수 없으므로, 모든 데이터를 읽어내야만 최종 결과 집합을 만들어낼 수 있는것이다.
2. Clustered Index Scan
클러스터형 인덱스 스캔은 클러스터형 인덱스의 키로 지정된 열을 탐색의 조건으로 사용할 수 없는 경우에 모든 행을 읽어내면서 조회하는 방식이다.

위 그림은 클러스터형 인덱스의 키가 Birth 열일 때, ID = 'B02' 조건을 조회하는 스캔 범위를 표현한 것이다.
페이지 1 인 루트(Root) 페이지를 통해 제일 좌측에 존재하는 리프 페이지를 찾고 이후 모든 행을 읽어내게 된다.
현재 클러스터형 인덱스는 키값인 Birth 열을 기준으로 정렬되어 있기 때문에 ID 열의 조건인 'B02'값의 위치를 탐색할 수 없다. 따라서 모든 데이터를 읽어내야만 최종 결과 집합을 만들어 낼 수 있는 것 이다.
인덱스와 관련된 스캔을 잠깐 알아보자.
Index Full Scan
Index Full Scan은 수직적 탐색 없이 인덱스 리프 레벨을 처음부터 끝까지 수평적으로 탐색하는 방식으로써, 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다.

수직적 탐색 없이 인덱스 리프 레벨을 처음부터 끝까지 수평적으로만 탐색한다고 했는데, 이는 개념적으로 설명하기 위한 것일 뿐 실제론 위 그림의 점선처럼 수직적 탐색이 먼저 일어난다.
루트 레벨과 같은 상위 레벨을 거치지 않고선 가장 왼쪽에 위치한 첫번째 리프 페이지로 찾아갈 방법이 없기 때문이다.
Index Full Scan의 효용성
인덱스 선두 열이 조건절에 없다면 옵티마이저는 우선적으로 Table Full Scan을 고려한다.
그런데 테이블의 용량이 큰 경우, Table Full Scan의 부담이 클 수 있으므로 인덱스를 활용하여 조회할 필요가 있다.
데이터 저장공간은 '가로 x 세로' 즉, '열길이 x 레코드 수' 에 의해 결정되므로 대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적기 마련이다.
만약 인덱스 스캔 단계에서 대부분의 레코드를 필터링하고 일부에 대해서만 테이블 엑세스를 할 수 있다면 당연히 테이블 전체를 풀스캔하는것보다 성능상 이점이 있을 수 있겠다..! 이럴때, 옵티마이저는 Index Full Scan 방식을 선택할 수 있다.
어느 사원 테이블에 연봉 열이 있다고 가정하자.
테이블 이름 : emp
사원 이름 : ename
연봉 : sal
아래 쿼리문은 Index Full Scan이 효과를 발휘하는 전형적인 케이스이다.
-- sal 은 인덱스 선언되지 않은 상태
SELECT *
FROM emp
WHERE sal > 5000
ORDER BY ename ASC위 쿼리는 아래 그림과 같이 나타낼 수 있다.

위 쿼리와 그림처럼 연봉이 5000을 초과하는 사원이 전체 중 극히 일부라면 Table Full Scan보다는 Index Full Scan을 통한 필터링이 큰 효과를 가져다준다. 하지만 이런 방식은 적절한 인덱스가 없어 Index Range Scan의 차선책으로 선택된 것이므로, 가능하다면 인덱스 구성을 조정해주는것이 좋겠다.
인덱스를 이용한 소트 연산 대체
Index Full Scan은 Index Range Scan과 마찬가지로 그 결과집합이 인덱스 컬럼 순으로 정렬되므로 Sort Order By 연산을 생략할 목적으로 사용될 수도 있는데, 이는 차선책으로 선택됐다기보다 옵티마이저가 전략적으로 선택한 경우에 해당한다.
SELECT TOP 1 *
FROM emp WITH (FASTFIRSTROW)
WHERE sql > 1000
ORDER BY ename ASC
-- 사용자가 FASTFIRSTROW 힌트를 사용하였다고 가정위 쿼리는 아래 그림과 같이 나타낼 수 있다.

테이블 내 대부분의 사원의 연봉이 1000을 초과한다고 가정했을 때, Index Full Scan을 하면 거의 모든 레코드에 대해 테이블 엑세스가 발생해 Table Full Scan보다 오히려 불리할 수 있다.
만약 sal 열이 인덱스 선두 열이여서 Index Range Scan을 하더라도 마찬가지이다.
그럼에도 위에서 인덱스가 사용된 것은 사용자가 FASTFIRSTROW 힌트를 이용해 옵티마이저 모드를 바꾸었기 때문이다.
즉, 옵티마이저는 소트 연산을 생략함으로써 전체 집합 중 처음 일부만을 빠르게 리턴할 목적으로 Index Full Scan 방식을 선택한 것이다.
이렇게 된다면 데이터 읽기를 멈추지 않고 끝까지 하게되고, Full Table Scan을 한 것보다 훨씬 더 많은 I/O를 일으키게 되며 서버 자원을 낭비할것이다.
따라서, 사용자는 힌트를 적절하게 사용해야 할 것이다.
3. Clustered Index Seek
Clustered Index Seek는 클러스터형 인덱스의 키값을 통해 조건을 탐색하여 만족하는 범위만을 읽어내는 방식이다.

위는 클러스터형 인덱스의 키로 정의된 Birth열을 조건으로 탐색하는 과정이다.
루트 페이지부터 조건의 시작점인 '900601' 데이터의 위치를 탐색한다.
최종 리프 페이지에 도달하면 각 행의 값을 비교하게되고 마지막 범위 값인 '900701'을 넘어가는 데이터를 만나는 순간 탐색을 종료하게 된다.
4. Non-Clustered Index Scan
Non-Clustered Index Scan은 구문에서 요구하는 열들이 비 클러스터형 인덱스에 모두 포함되어 있지만 키로 정의된 열이 탐색의 조건으로 사용될 수 없는 경우에 모든 행을 읽어내면서 조회하는 방식이다.

위 그림은 인덱스의 키가 ID 열일 때, 탐색의 조건으로 사용될 수 없는 하나의 예시이다.
Non-Clustered Index Scan도 루트 페이지를 통해 제일 좌측에 존재하는 리프 페이지를 찾고 이후 모든 행을 읽어내게 된다.
인덱스의 키로 정의된 ID 열이 조건으로 사용됐지만 조건절이 ID + 'P' 형태로 가공되어있으므로 탐색의 조건으로 사용되지 못하고(인덱스를 못타고) 모든 행을 읽게 된 것이다.
5. Non-Clustered Index Seek
Non-Clustered Index Seek는 구문에서 요구하는 열들이 비 클러스터형 인덱스에 모두 포함되어 있으면서 키로 지정한 열이 탐색의 조건으로 사용되고있는 상황에서 옵티마이저가 SEEK 연산이 효율적이라고 판단한 상황에 수행되는 방식이다.
다시말해, 인덱스에 포함된 열을 탐색해도 SCAN이 일어날 수 있다는 것이다.

위 그림은 인덱스의 키가 ID 열일 때, ID = 'B01' 조건으로 특정 범위를 탐색하는 과정을 나타낸다.
조건으로 사용된 열이 인덱스 키와 동일하기 때문에 특정 범위만을 탐색하게 된다.
루트 페이지부터 조건에 해당되는 'B01' 데이터의 위치를 갖고 리프 페이지의 행을 비교하면서 조건과 일치하지 않는 행을 만날 때 탐색을 종료한다.
6. RID Lookup : Non-Clustered Index + Heap Table
RID Lookup은 비 클러스터형 인덱스를 읽은 후에 참조해야 하는 열 데이터가 부족하여 테이블로 조인하는 과정이다.

위 그림은 비 클러스터형 인덱스에서 테이블로 RID 값을 통해 Lookup 하는 과정을 표현한 것이다.
쿼리문에서 요구하는 결과는 ID = 'C02'의 조건에 만족하는 행의 EName 열이다.
비 클러스터형 인덱스로 ID 열을 탐색하지만, 인덱스에 존재하지 않는 EName 열은 테이블로부터 가져와야만 한다.
이때 RID Lookup이 수행되는데, 비 클러스터형 인덱스에는 테이블의 각 행을 구분할 수 있는 RID값이 포함되어 있기 때문에 Lookup을 통해 테이블과 조인하여 EName 열을 출력하는 것이다.
7. Key Lookup : Non-Clustered Index + Clustered Index
Key Lookup은 비 클러스터형 인덱스에 필요한 열 데이터가 부족하여 조인을 통해 열을 가져오는 과정으로 RID Lookup과 동일하다.
다만, Key Lookup은 테이블이 클러스터형 인덱스로 구성되어 있고 이로 인해 비 클러스터형 인덱스에는 RID값이 아닌 클러스터형 인덱스의 Key값을 포함하고 있다는 점에서 차이가 있다.

위 그림은 비 클러스터형 인덱스에서 클러스터형 인덱스로 Key 값을 통해 Lookup 하는 과정을 표현한 것이다.
비 클러스터형 인덱스로 ID 열을 탐색하고 인덱스에 존재하지 않는 EName 열은 클러스터형 인덱스로부터 가져온다.
이때, 비 클러스터형 인덱스에 포함되어 있는 클러스터형 인덱스의 Key를 통해 Lookup을 수행하고 클러스터형 인덱스를 탐색하여 최종 EName 열을 출력하게 된다.
포괄(INCLUDE) 열이 있는 인덱스
인덱스를 생성할 때 키가 아닌 열로 데이터만 포함시킨 열을 포괄 열이라고 한다.
포괄 열은 RID 혹은 Key Lookup에 의한 비용을 제거하기 위해 사용된다.
제한 사항
- 키가 아닌 열은 비 클러스터형 인덱스에 대해서만 정의할 수 있다.
- 키 열과는 다르게 text, ntext 및 image 를 제외한 모든 데이터 형식을 포괄 열로 사용할 수 있다.
- 결정적이면서 정확하거나 정확하지 않은 계산 열은 포괄 열이 될 수 있다. (링크 참조)
- image, ntext 및 text 데이터 형식에서 파생된 계산 열은 데이터 형식이 키가 아닌 인덱스 열로 허용되는 한 포괄 열이 될 수 있다.
- 해당 테이블의 인덱스를 먼저 삭제하지 않는 경우, 포괄 열을 테이블에서 삭제할 수 없다.
- 다음 경우를 제외하고 키가 아닌 열은 변경할 수 없다.
- 열의 null 허용 여부를 NOT NULL 에서 NULL 로 변경한다.
- varchar, nvarchar 또는 varbinary 열의 길이를 늘린다.
포괄 열로 정의된 열은 정렬되지 않은 상태로 리프 페이지에만 저장되기 때문에 조건을 탐색하는 용도로는 사용할 수 없지만, 페이지 분할(Page Split, DML이 수행될 때 데이터를 정렬시키는 과정에서 페이지가 분할되는 현상)에는 이점을 가질 수 있다.
예시
A열이 선행 키로 정의된 인덱스가 가정할 때, B열을 후행키로 정의한 것과 포괄 열로 정의한 것에 대해 간단히 비교해보자
먼저 아래 그림은 B열이 키로 사용됐을 때의 예시이다.

B열을 키로 사용하게 되면 데이터가 삽입될 때 정렬된 상태에 맞도록 페이지를 찾아서 추가해야한다.
신규 데이터 'c' 값은 'b' 다음이기 때문에 2번 페이지에 삽입되어야 하는데 현재 페이지가 가득 찬 상태여서 페이지 분할이 발생되고, 일부 데이터가 새로 만들어진 페이지로 이전된다.
아래 그림은 B 열을 포괄 열로 정의했을 때의 예시이다.

포괄 열로 정의된 B 열은 정렬을 하지 않는다.
키로 사용된 A열에 대해서만 정렬을 유지하면 되기 때문에 3번 페이지의 비어 있는 공간으로 데이터를 삽입하게 된다.
이로 인해 페이지는 분할될 필요가 없어지게 되면서 키로 사용했을 때보다 이점을 갖게 된다.
포괄 열을 정의하는 기본 구문은 다음과 같다
CREATE NONCLUSTERED INDEX 인덱스명 ON 테이블명 (인덱스 키) INCLUDE (포괄 열)비 클러스터형 인덱스를 생성할 때 INCLUDE 옵션으로 선언되는 열들이 포괄 열에 해당된다.
아래 쿼리와 그림을 통해 포괄 열의 필요성을 예시로 들고자 한다.
CREATE INDEX NIDX01 ON Employee(Birth)
SELECT EName
FROM Employee
WHERE Birth = '901101'
GO
위 구문은 Birth = '901101' 조건에 해당하는 데이터의 EName 열을 출력하는 구문이다.
데이터를 빠르게 찾아내기 위해 Birth 열에 인덱스를 생성했지만, EName 열은 인덱스에 포함되지 않아 Employee 테이블로의 RID Lookup이 불가피한 상황이다.
여기서 RID Lookup을 하는 과정은 NL Join 방식으로 수행되는데, 인덱스로 탐색된 데이터가 많을수록 조인 시도가 반복되기 때문에 그에 따른 비용이 증가하게 된다.
위 그림에서는 2건의 행이 RID Lookup을 수행하지만 인덱스로 탐색된 데이터가 만약 1만건이라면, 그에 따라 테이블로 1만번의 조인 시도가 동반될 것이다.
이와 같이 인덱스의 탐색 대상이 되지 않는 열들로 인한 RID Lookup 비용을 포괄 열을 사용하여 개선할 수 있는데, 아래 쿼리문과 그림이 예시이다.
CREATE INDEX NIDX01 ON Employee(Birth) INCLUDE (EName)
SELECT EName
FROM Employee
WHERE Birth = '201101'
GO
인덱스에 EName 열을 포괄 열로 정의하였다. 동일한 구문을 실행하지만, 인덱스로 Birth 열을 탐색한 행에 EName 열이 이미 포함되어있기 때문에 RID Lookup 과정을 추가로 수행하지 않아도 된다.
이처럼 조건절로서 인덱스의 탐색 대상이 아닌 열은 단순히 포괄 열로 포함시키는 것만으로도 성능을 개선할 수 있는데, 포괄 열이 아닌 키로 정의할 경우에는 다음에 설명하는 페이지 분할이 발생될 수 있기 때문에 요구되는 구문에 맞춰 적절한 인덱스 구성을 사용하여야 한다.
다시말해,
검색 조건에 들어간다고 해서 무조건 인덱스로 정의하기보다, 포괄 열로 정의하면 페이지 분할을 줄일 수 있다는것이다.
인덱스 조각화
인덱스 조각화란?
인덱스 조각화는 키값을 기준으로 정렬된 인덱스 페이지의 논리적 순서와 물리적 순서가 일치하지 않는 것을 의미한다.
이는 페이지 분할로 인해 발생될 수 있는데, 아래 그림을 보자.

위 그림은 ID 열을 기준으로 생성된 비 클러스터형 인덱스이다.
여기서 하나의 페이지에는 최대 3개의 행이 저장될 수 있다고 가정하자.
현재 1번 페이지는 루트 페이지로 사용되며 2번과 3번 페이지는 각각 리프 페이지로 데이터가 가득 찬 상태이다.
이런 상황에서 ID 열이 'A01' 인 데이터가 추가된다면 어떻게 될까?
ID열은 정렬되어 있기 때문에 2번 페이지의 'A02' 이전의 행으로 삽입되어야 한다.
다음 그림은 'A01' 데이터가 추가된 인덱스 구조를 나타낸다.
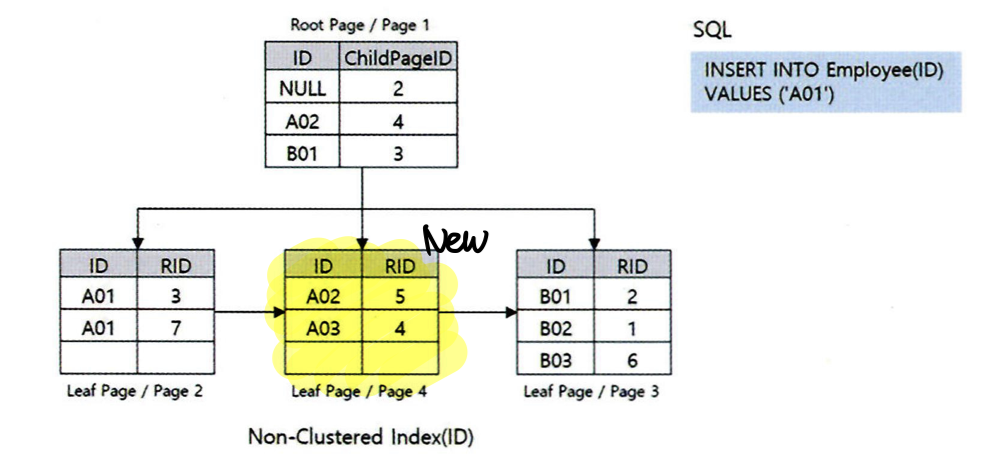
2번 페이지에 더 이상 삽입할 공간이 없으므로 새로운 4번 페이지를 할당받게 되고,
정렬된 상태를 유지하며 데이터를 분배하게 되는데 이러한 현상을 페이지 분할 이라고 한다.
인덱스 조각화는 이렇게 페이지의 분할이 생겼을 때 발생될 수 있다.
2번 페이지로부터 분할된 4번 페이지는 2번 페이지에서 포인터로 연결하게 되고, 4번 페이지는 다시 3번 페이지로 포인터를 연결하게 되는데, 이렇게 연속성을 갖는 페이지의 논리적 순서와 물리적 순서가 달라질 때 인덱스의 조각화가 발생됐다고 표현한다.
이때의 페이지 조각률은 3개 중 1개의 페이지인 33%가 된다.
페이지 분할의 영향
B-Tree 구조를 갖는 인덱스의 페이지는 데이터 밸런스를 맞추기 위해 약 50%의 데이터를 새로운 페이지로 이동시킨다.
이는 페이지 내의 빈 공간이 50% 생긴다는 것과 동일한 의미를 나타낸다.
이후 UPDATE 혹은 INSERT에 의해 페이지 공간이 전부 채워진다면 문제가 되지 않겠지만, 빈 공간이 지속적으로 유지된다면 페이지 사용 효율성이 떨어지기 때문에 해당 데이터를 조회할 떄 더 많은 페이지를 읽어내야 하는 상황이 발생될 수 있다.
다시말해, 데이터가 추가될 때 인덱스의 조각화가 발생하여 더 많은 페이지를 읽어야 할 수도 있다는 것이다.
페이지 분할에 의한 성능 이슈
페이지 분할은 결국 읽어내야 하는 페이지가 많아지는 것을 의미한다.
간단한 예제를 통해 페이지 분할로 성능 이슈가 발생되는 것을 확인해 보자.
먼저, 테스트를 위한 Split 테이블을 master 데이터베이스에 존재하는 spt_values 테이블로부터 생성한다.
SELECT CONVERT (INT, a.number) AS [no]
,CONVERT (CHAR(900),'A') AS txt INTO Split
FROM master.dbo.spt_values AS a
WHERE a.[type] = 'P'
AND a.[number] BETWEEN 1 AND 1000
GO
Split 테이블에는 no열에 1부터 1000까지의 데이터가 존재하며 txt열은 'A'의 데이터를 포함하고 있다.
다음으론 인덱스를 생성해보자
CREATE INDEX NIDX01_Split ON Split(no) INCLUDE (txt)인덱스에 no 열을 키로 지정하여 정렬 대상을 만들고, 인덱스 페이지당 8건의 행만 포함될 수 있도록 CHAR(900)으로 선언된 txt열을 포괄 열로 포함시켰다.

클러스터형 인덱스의 크기 예측 - SQL Server
이 절차를 사용하여 SQL Server에서 클러스터형 인덱스에 데이터를 저장하는 데 필요한 공간의 크기를 예측할 수 있습니다.
learn.microsoft.com
위 내용에 따라, char(900)으로 선언하게 되면, 인덱스 페이지당 8건의 행만 포함되도록 만들 수 있다.
현재까지의 페이지 정보를 DBCC SHOWCONTIG 명령으로 확인해 보면 다음과 같다.
DBCC SHOWCONTIG('Split', 'NIDX01_Split')DBCC SHOWCONTIG이(가) 'Split' 테이블을 검색하는 중...
테이블: 'Split'(279672044); 인덱스 ID: 2, 데이터베이스 ID: 1
LEAF 수준 검색을 수행했습니다.
- 검색한 페이지................................: 125
- 검색한 익스텐트 ..............................: 16
- 익스텐트 스위치..............................: 15
- 익스텐트당 평균 페이지 수........................: 7.8
- 검색 밀도[최적:실제].......: 100.00% [16:16]
- 논리 검색 조각화 상태 ..................: 0.00%
- 익스텐트 검색 조각화 상태 ...................: 25.00%
- 페이지당 사용 가능한 평균 바이트 수.....................: 752.0
- 평균 페이지 밀도(전체).....................: 90.71%이중, 검색한 페이지(Pages Scanned) 는 Leaf Level의 총 페이지 수를 의미하며 125개의 리프 페이지가 할당된 것이다.
논리 검색 조각화 상태(Logical Scan Fragmentation)는 조각난 페이지의 비율을 의미하는데 현재 0%로 없는 상태이고, 평균 페이지 밀도(Avg. Page Density)를 통해 페이지당 약 90%에 해당하는 영역이 사용되고 있음을 확인할 수 있다.
다음 실제 쿼리문을 실행하여 I/O 정보를 확인해보자
SELECT COUNT(*)
FROM Split
WHERE no <= 1000
GO
테이블 'Split'. 스캔 수 1, 논리적 읽기 127,
실제 읽기 0, 페이지 서버 읽기 0, 미리 읽기 읽기 0,
페이지 서버 미리 읽기 읽기 0, lob 논리적 읽기 0, lob 실제 읽기 0,
lob 페이지 서버 읽기 0, lob 미리 읽기 읽기 0, lob 페이지 서버 미리 읽기 읽기 0.위 정보를 확인하면, 인덱스를 통해 모든 데이터를 조회했을 때, 125개의 리프 페이지를 포함하여 총 127페이지를 읽어낸다.
이제 페이지 분할이 발생될 수 있도록 데이터를 삽입한다.
INSERT INTO Split
SELECT CONVERT(INT,b.number) AS no
,CONVERT(char(900), 'B') AS txt
FROM master.dbo.spt_values AS b
WHERE b.type = 'P'
AND b.number BETWEEN 1 AND 1000
AND b.number%8 = 2
GO
삽입되는 데이터는 각 리프 페이지의 두 번째 행과 같은 데이터이다. 즉, 125개의 리프 페이지가 모두 분할이 발생될 수 있도록 125건의 데이터를 삽입하는 것이다.
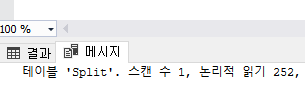
페이지 분할이 발생된 다음의 DBCC SHOWCONTIG 정보는 다음과 같다.
DBCC SHOWCONTIG이(가) 'Split' 테이블을 검색하는 중...
테이블: 'Split'(279672044); 인덱스 ID: 2, 데이터베이스 ID: 1
LEAF 수준 검색을 수행했습니다.
- 검색한 페이지................................: 250
- 검색한 익스텐트 ..............................: 33
- 익스텐트 스위치..............................: 249
- 익스텐트당 평균 페이지 수........................: 7.6
- 검색 밀도[최적:실제].......: 12.80% [32:250]
- 논리 검색 조각화 상태 ..................: 99.60%
- 익스텐트 검색 조각화 상태 ...................: 18.18%
- 페이지당 사용 가능한 평균 바이트 수.....................: 3958.0
- 평균 페이지 밀도(전체).....................: 51.10%페이지 분할로 인해 리프 페이지의 수가 250개로 증가되었다.
평균 페이지 밀도가 약 51%로 각 페이지의 절반의 영역만 사용되고 있으며, 조각률은 99.6%로 전체 250개의 페이지 중 첫 번째 리프 페이지를 제외하고 모든 페이지가 분할되었음을 확인할 수 있다.
다시 이전과 같은 구문을 통해 I/O를 확인해보자
SELECT COUNT(*)
FROM Split
WHERE no <= 1000
GO

이전 1000건의 데이터에서 약 10%에 해당하는 데이터가 삽입됐지만 실질적으로 페이지 수는 2배 증가하였다.
이처럼 DML로 인해 페이지 분할이 지속적으로 발생된다면 많은 페이지 단편화로 데이터 조회 성능 저하의 요인이 될 수 있다.
그렇다면 분할된 페이지는 어떻게 관리해야 할까?
분할된 페이지 정리
분할로 인해 증가된 페이지 양을 다시 최적화하는 방법으로는 두가지가 있다.
- 인덱스 재구성(Index Reorganize)
- 인덱스 재작성(Index Rebuild)
재구성은 조각난 인덱스의 페이지를 읽어내면서 물리적으로 재 정렬한 후 비워진 페이지를 반환하는 과정이다.
재작성은 기존 인덱스를 삭제하고 새로운 페이지를 할당받아 재 생성하는 과정이다.
하나의 예시로 조각난 인덱스를 다시 작성했을 때의 결과를 확인해보자.
인덱스를 다시 작성하는 기본 명령은 다음과 같다.
ALTER INDEX NIDX01_Split ON dbo.Split REBUILD
다시 DBCC SHOWCONTIG를 통해 리프 페이지의 정보를 확인해 보자.
DBCC SHOWCONTIG('Split', 'NIDX01_Split')
DBCC SHOWCONTIG이(가) 'Split' 테이블을 검색하는 중...
테이블: 'Split'(279672044); 인덱스 ID: 2, 데이터베이스 ID: 1
LEAF 수준 검색을 수행했습니다.
- 검색한 페이지................................: 141
- 검색한 익스텐트 ..............................: 18
- 익스텐트 스위치..............................: 17
- 익스텐트당 평균 페이지 수........................: 7.8
- 검색 밀도[최적:실제].......: 100.00% [18:18]
- 논리 검색 조각화 상태 ..................: 0.00%
- 익스텐트 검색 조각화 상태 ...................: 0.00%
- 페이지당 사용 가능한 평균 바이트 수.....................: 771.5
- 평균 페이지 밀도(전체).....................: 90.47%페이지 분할로 총 250개의 페이지였던 리프 페이지가 141개로 줄었다.
조각난 페이지는 0%로 존재하지 않으며, 평균 페이지의 밀도는 약 90%로 증가되어 페이지 대부분의 영역에 데이터가 저장된 것을 확인할 수 있다.
최종적으로 인덱스가 재 생성되면서 기존 125개의 페이지에서 16개(126건이 저장될 수 있는 페이지 수)(페이지당 8개)의 페이지가 증가된 것 이다.
'DB' 카테고리의 다른 글
| [MSSQL] SQL Server 튜닝 - 조인 (0) | 2023.01.04 |
|---|---|
| [MSSQL] SQL Server 튜닝 - 실행 계획 (0) | 2022.12.27 |
| [DB/SQL] Server SQL Modes - "Group By" 를 사용할 때, 알아야 할 내용 (0) | 2022.11.17 |
| [MSSQL] JOIN 설명 및 사용법 (0) | 2022.03.03 |
| [MSSQL] VARCHAR(MAX|N) 길이별 성능차이 및 NVARCHAR와의 성능차이에 관해.. (0) | 2022.02.08 |

댓글